
Il fulcro di ogni borsa finanziaria è il suo motore di matching. È ciò che permette ai trader di entrare e uscire dai mercati, acquistando e vendendo al miglior prezzo disponibile al momento. Man mano che i loro ordini di mercato vengono eseguiti a partire dagli ordini limite di altri trader presenti nel book degli ordini, il saldo tra i migliori prezzi di acquisto/vendita disponibili si aggiusta, stabilendo un nuovo prezzo di mercato.
In informatica, i motori di matching sono noti come macchine a stati. Hanno uno stato interno che cambia ogni volta che ricevono nuovi input e generano nuovi output. Nel trading, gli input sono gli ordini dei trader e gli output sono gli aggiornamenti man mano che gli ordini vengono eseguiti parzialmente, completamente o rifiutati.
Affinché un motore di matching sia in grado di gestire grandi volumi di ordini e di conservare una registrazione accurata di ciò che è avvenuto, deve essere connesso a vari componenti di rete e di archiviazione. Come vedremo di seguito, ogni scelta progettuale influisce sulle prestazioni del sistema finale, nonché su ciò che può o non può fare.
Prestazioni vs affidabilità
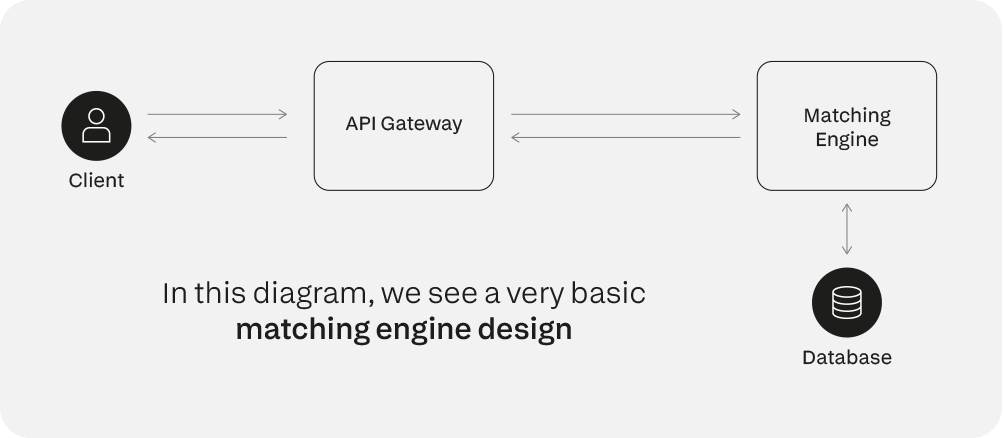
Il diagramma sopra riportato rappresenta un motore di matching molto semplice. I trader interagiscono con esso tramite un gateway API, il motore di matching risponde e un componente di database separato registra tutte le varie interazioni avvenute.
Durante la progettazione dell'infrastruttura di scambio, gli sviluppatori si trovano di fronte a un dilemma Tra affidabilità e prestazioni. Concentrarsi troppo sulle prestazioni influisce negativamente sull'affidabilità. Concentrarsi troppo sull'affidabilità influisce negativamente sulle prestazioni.
Il progetto sopra descritto fallisce su entrambi i fronti. Il problema è che viene rapidamente sopraffatto da un elevato volume di ordini (scarse prestazioni). Inoltre, essendo un sistema autonomo senza backup, rappresenta un singolo punto di errore (scarsa affidabilità).
Introduzione alla replicazione
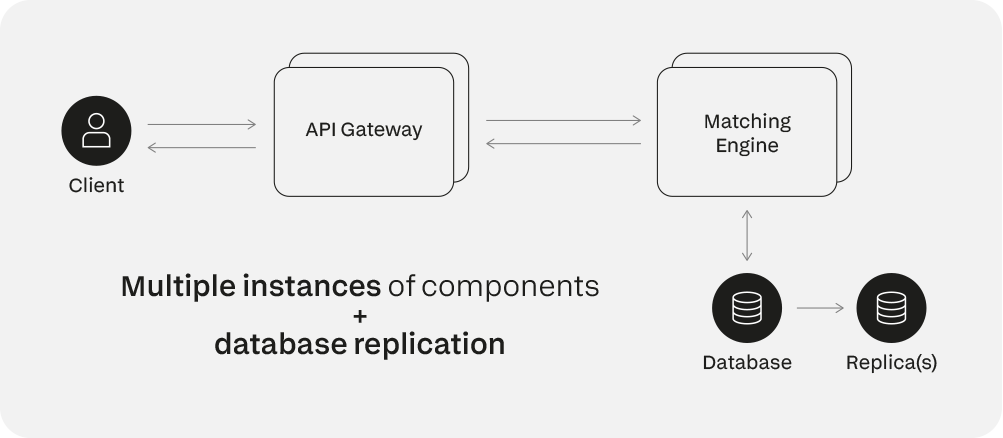
L'immagine sottostante è una semplice iterazione del primo progetto. In questo caso, più copie di tutti i componenti vengono eseguite in parallelo. La replica consente la ridondanza nel caso in cui un singolo componente dovesse essere sovraccaricato, tuttavia, ciò compromette le prestazioni del sistema, in particolare a causa della replica del database.
Coerenza e consenso
La replicazione porta con sé il problema aggiuntivo di come mantenere la coerenza tra le copie. Laddove una singola istanza può essere considerata canonica, la replicazione introduce il problema di come raggiungere il consenso tra le copie. Se una di queste istanze devia dallo stato delle altre, l'affidabilità del sistema ne risente immediatamente.
La sfida tecnica in questo caso è garantire che ogni copia riceva i suoi input nello stesso momento e nell'ordine corretto, senza compromettere le prestazioni del sistema o introdurre ulteriori punti di potenziale guasto.
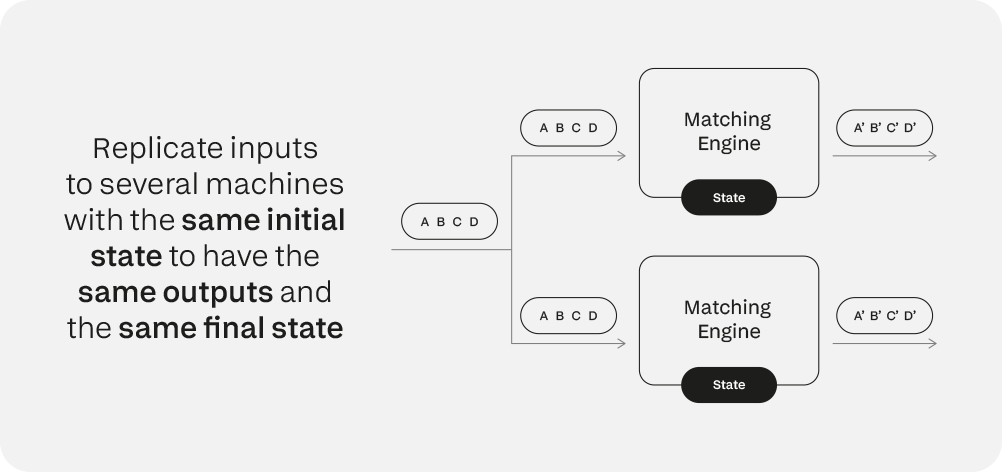
Ciò che serve qui è un po' di pensiero sistemico distribuito. Gli algoritmi di consenso possono essere utilizzati per garantire che gli input arrivino a tutte le istanze del motore corrispondenti al momento giusto e nell'ordine corretto.
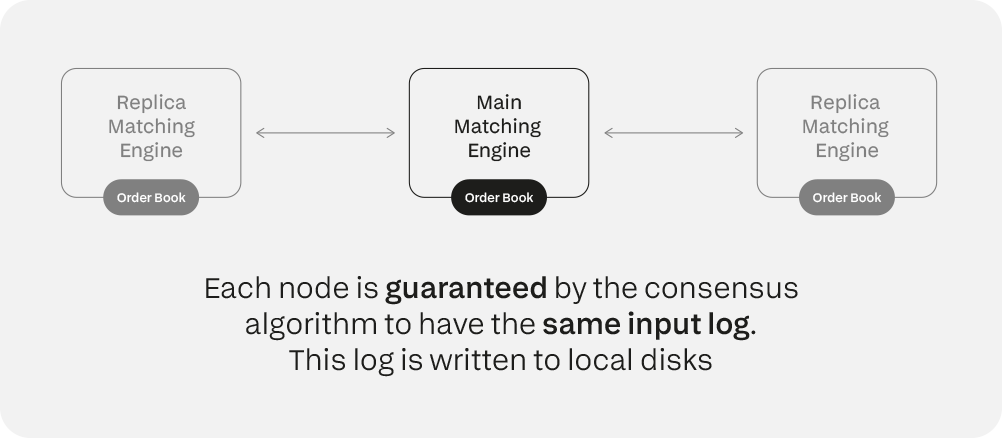
I nodi leader sono responsabili della propagazione degli input a tutte le copie del motore corrispondenti. Nuovi leader vengono eletti per continuare questo compito nei casi in cui il leader non sia disponibile per qualsiasi motivo.
Se la maggioranza dei nodi concorda sullo stato attuale, tutto procede come al solito. Se un leader non è disponibile, è possibile eleggerne uno nuovo che continui a propagare gli input a tutte le copie.
E il ripristino del sistema?
Lo stato attuale di un motore di matching è determinato dalla serie di modifiche apportate al suo stato iniziale da ogni input successivo. Se, per qualsiasi motivo, il sistema subisce un'interruzione, è possibile rieseguire tutti gli input ricevuti dal sistema nell'ordine corretto e quindi arrivare all'ultimo stato prima dell'interruzione.
Tuttavia, sorge un problema se si considera l'entità dei registri eventi di una borsa finanziaria. A causa delle loro dimensioni, può essere poco pratico riprodurre tutti gli eventi dall'inizio ogni volta che è necessario un ripristino.
Per risolvere questo problema, vengono acquisiti snapshot dello stato attuale a intervalli regolari. In questo modo, è possibile ripristinare un sistema utilizzando questi snapshot. Il più recente rappresenta un punto di consenso locale da cui è possibile riprodurre gli input fino al punto desiderato.
Considerazioni sullo stoccaggio
La tenuta dei registri è fondamentale per le esigenze normative, di compensazione, di regolamento e di recupero crediti. Tuttavia, le interazioni avvengono nella RAM affinché il motore di matching possa funzionare in linea con le esigenze delle moderne borse finanziarie.
Tuttavia, la RAM non è sufficiente per conservare una registrazione persistente degli eventi, motivo per cui è necessario un sistema separato per conservare tutte le interazioni del client per riferimento futuro.
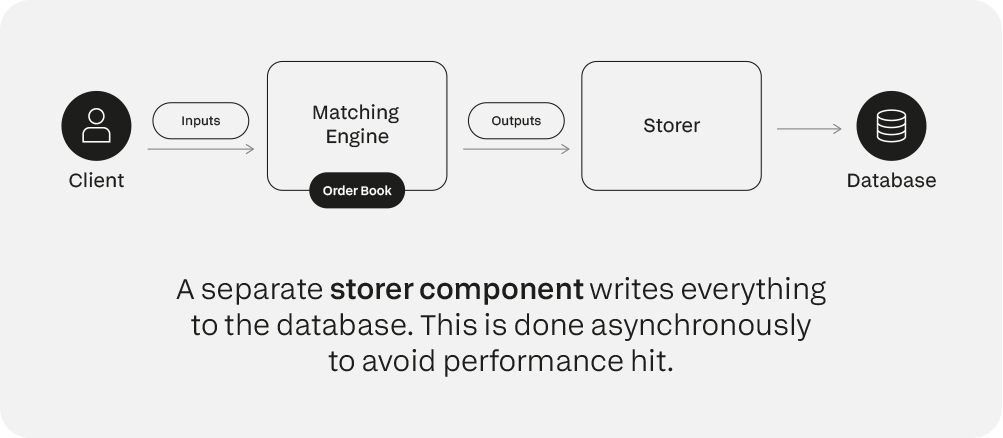
Oltre ai database visti sopra, viene utilizzato un componente di archiviazione separato, in modo che il motore di corrispondenza non debba comunicare direttamente con i database (cosa che avrebbe un impatto sulle prestazioni).
Questo componente riceve gli output corrispondenti dal motore e li scrive in modo asincrono su un database per mantenere le prestazioni del sistema. Il database può quindi essere interrogato tramite un'API separata.
Considerazioni sulla produttività
Infine, arriviamo alla produttività. Oggigiorno, sia le piattaforme retail che quelle istituzionali hanno requisiti rigorosi in termini di produttività. È fondamentale che i motori di matching siano progettati per gestire picchi di attività di trading di gran lunga superiori alla media.
Finora abbiamo parlato della replicazione come strategia di resilienza; tuttavia, le copie del motore corrispondenti possono essere utilizzate anche per scalare un sistema orizzontalmente, consentendo l'elaborazione simultanea di più ordini.
Un modo efficace per aumentare la produttività di un sistema è suddividere i vari asset offerti in più segmenti e quindi utilizzare un'istanza separata del motore di matching per ciascuno di essi. Questo può essere fatto per l'intero elenco di simboli o solo per quelli più scambiati.
Ad esempio, per consentire a un exchange di criptovalute di scalare orizzontalmente, un'istanza separata del motore di corrispondenza può essere dedicata alle coppie BTC, un'altra alle coppie ETH, con gli asset crittografici meno liquidi raggruppati nelle proprie istanze separate del motore di corrispondenza.
Conclusione
Ci auguriamo che questa introduzione alle considerazioni sulla progettazione del motore di matching vi sia sembrata interessante e istruttiva. Si tratta di una tecnologia che spesso non riceve l'attenzione che merita, nonostante sia la spina dorsale di ogni operazione in tutte le classi di asset, facilitando lo scambio efficiente di migliaia di miliardi di dollari di valore ogni giorno.
Il post Matching Engine 101: le sfide per abbinare gli ordini in modo rapido e affidabile è apparso per la prima volta su BeInCrypto .