I chatbot moderni imparano costantemente e il loro comportamento cambia sempre. Ma le loro prestazioni possono diminuire così come migliorare.
Studi recenti minano il presupposto che imparare significhi sempre migliorare. Ciò ha implicazioni per il futuro di ChatGPT e dei suoi pari. Per garantire che i chatbot rimangano funzionanti, gli sviluppatori di intelligenza artificiale (AI) devono affrontare le sfide emergenti relative ai dati.
ChatGPT Diventa più stupido nel tempo
Uno studio pubblicato di recente ha dimostrato che i chatbot possono diventare meno capaci di eseguire determinate attività nel tempo.
Per giungere a questa conclusione, i ricercatori hanno confrontato i risultati dei Large Language Models (LLM) GPT-3.5 e GPT-4 a marzo e giugno 2023. In soli tre mesi, hanno osservato cambiamenti significativi nei modelli alla base di ChatGPT.
Ad esempio, a marzo, GPT-4 è stato in grado di identificare i numeri primi con una precisione del 97,6%. A giugno, la sua precisione era crollata a solo il 2,4%.
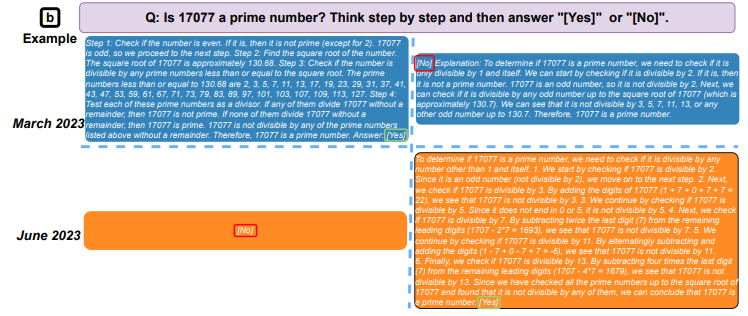
L'esperimento ha anche valutato la velocità con cui i modelli sono stati in grado di rispondere a domande sensibili, quanto bene potevano generare codice e la loro capacità di ragionamento visivo. Tra tutte le abilità che hanno testato, il team ha osservato casi di qualità dell'output AI che si deterioravano nel tempo.
La sfida dei dati di allenamento in tempo reale
Machine Learning (ML) si basa su un processo di formazione in base al quale i modelli di intelligenza artificiale possono emulare l'intelligenza umana elaborando grandi quantità di informazioni.
Ad esempio, gli LLM che alimentano i moderni chatbot sono stati sviluppati grazie alla disponibilità di enormi repository online. Questi includono set di dati compilati da articoli di Wikipedia, che consentono ai chatbot di apprendere digerendo il più grande corpo di conoscenza umana mai creato.
Ma ora, artisti del calibro di ChatGPT sono stati rilasciati allo stato brado. E gli sviluppatori hanno molto meno controllo sui loro dati di addestramento in continua evoluzione.
Il problema è che tali modelli possono anche “imparare” a dare risposte sbagliate. Se la qualità dei loro dati di addestramento si deteriora, lo fanno anche i loro risultati. Ciò rappresenta una sfida per i chatbot dinamici che vengono alimentati con una dieta costante di contenuti scaricati dal web.
L'avvelenamento dei dati potrebbe portare al calo delle prestazioni del chatbot
Poiché tendono a fare affidamento su contenuti estratti dal Web, i chatbot sono particolarmente inclini a un tipo di manipolazione noto come avvelenamento dei dati.
Questo è esattamente quello che è successo al Twitter bot Tay di Microsoft nel 2016. Meno di 24 ore dopo il suo lancio, il predecessore di ChatGPT ha iniziato a pubblicare tweet provocatori e offensivi. Gli sviluppatori Microsoft lo hanno rapidamente sospeso e sono tornati al tavolo da disegno.
A quanto pare, i troll online hanno inviato spam al bot fin dall'inizio, manipolando la sua capacità di apprendere dalle interazioni con il pubblico. Dopo essere stato bombardato di insulti da un esercito di 4channer, non c'è da meravigliarsi che Tay abbia iniziato a ripetere a pappagallo la loro retorica odiosa.
Come Tay, i chatbot contemporanei sono prodotti del loro ambiente e sono vulnerabili ad attacchi simili. Anche Wikipedia, che è stata così importante nello sviluppo di LLM, potrebbe essere utilizzata per avvelenare i dati di addestramento ML.
Tuttavia, i dati intenzionalmente danneggiati non sono l'unica fonte di disinformazione di cui gli sviluppatori di chatbot devono fare attenzione.
Model Collapse: una bomba a orologeria per i chatbot?
Man mano che gli strumenti di intelligenza artificiale crescono in popolarità, i contenuti generati dall'IA stanno proliferando. Ma cosa succede agli LLM formati su set di dati scaricati dal web se una percentuale crescente di quel contenuto è essa stessa creata dall'apprendimento automatico?
Una recenteindagine sugli effetti della ricorsività sui modelli ML ha esplorato proprio questa domanda. E la risposta che ha trovato ha importanti implicazioni per il futuro dell'IA generativa.
I ricercatori hanno scoperto che quando i materiali generati dall'intelligenza artificiale vengono utilizzati come dati di addestramento, i modelli ML iniziano a dimenticare le cose apprese in precedenza.
Coniando il termine "collasso del modello", hanno notato che diverse famiglie di IA tendono tutte a degenerare se esposte a contenuti creati artificialmente.
Il team ha creato un ciclo di feedback tra un modello ML che genera immagini e il suo output in un esperimento.
Dopo l'osservazione, hanno scoperto che dopo ogni iterazione, il modello amplificava i propri errori e iniziava a dimenticare i dati generati dall'uomo con cui era iniziato. Dopo 20 cicli, l'output difficilmente assomigliava al set di dati originale.

I ricercatori hanno osservato la stessa tendenza a degenerare quando hanno giocato uno scenario simile con un LLM. E con ogni iterazione, errori come frasi ripetute e discorsi spezzati si sono verificati più frequentemente.
Da questo, lo studio ipotizza che le future generazioni di ChatGPT potrebbero essere a rischio di collasso del modello. Se l'intelligenza artificiale genera sempre più contenuti online, le prestazioni dei chatbot e di altri modelli di machine learning generativo potrebbero peggiorare.
Contenuti affidabili necessari per prevenire il calo delle prestazioni dei chatbot
In futuro, fonti di contenuto affidabili diventeranno sempre più importanti per proteggere dagli effetti degenerativi dei dati di bassa qualità. E quelle aziende che controllano l'accesso ai contenuti necessari per addestrare i modelli ML detengono le chiavi per un'ulteriore innovazione.
Dopotutto, non è un caso che i giganti della tecnologia con milioni di utenti costituiscano alcuni dei più grandi nomi dell'IA.
Solo nell'ultima settimana, Meta ha rivelato l'ultima versione del suo LLM Llama 2, Google ha lanciato nuove funzionalità per Bard e sono circolate notizie secondo cui anche Apple si sta preparando a entrare nella mischia.
Che sia causato dall'avvelenamento dei dati, dai primi segnali di collasso del modello o da qualche altro fattore, gli sviluppatori di chatbot non possono ignorare la minaccia del calo delle prestazioni.
Leggi di più: 6 migliori piattaforme di copy trading nel 2023
Il post Declino delle prestazioni del chatbot: le sfide dei dati minacciano il futuro dell'IA generativa è apparso per la prima volta su BeInCrypto .